小話
@abap34 です。
最近は腰と肩がかなり痛いです。いい椅子に座りたい 😢
この Julia 処理系を読む会もなんやかんや 2ヶ月くらい毎週続いているのですが、いくつかニュースがあったので本題に入る前に書いておきます!
ちょっとしたニュース ①
先日 Julia の Co-Founder の
Twitterのリンクでも貼ろうかと思ったら Wikipedia のページがありました。すごすぎ。
It was such an honor to meet @JeffBezanson and fellow Julia compiler enthusiasts in Tokyo! pic.twitter.com/r1vzPaP0X7
— abap34 (@abap34) October 15, 2024
そこで 「Julia の処理系を読む会を毎週やっていて、あなたが 10 年前に Scheme で書いたコードをみんなで何時間も読んでいるんです」と伝えたらとても喜んで貰えました!笑
ちょっとしたニュース ②
第5回のコードを読んでいるとき、まだ SSA形式の IR になっていないはずなのに SSA形式の IR にするようなチェックがなされている箇所を見つけ、 「不思議だな〜」と話していたところがあったのですが、今日の記事にも登場する Juliaコンパイラの中の人であるところの aviatesk さんに聞いてみたところ、どうもミス (実際誤った挙動にはならないのでバグというほどでもないですが) っぽいという結論に至りました。
読み始めたときにバグの一つや二つでも見つけられたらいいな〜と思っていたのでこれは嬉しいです。
追伸: 修正のPRが作られて、マージされました。
いろいろといいことが起きてていい感じですね。今後も頑張っていきます!
あらすじ
今回もJuliaのコンパイラの内部実装を読んでいくシリーズです。
シリーズ自体については
今回は実際にアルゴリズムに踏み込んでいきます。
具体的には、一旦 Julia のソースコードから離れて aviatesk さんの記事
この記事はなるべく元記事の理解の補足になることを目指しています。
少し長くなりそうなので 2,3 個に分ける予定です。
まず今回は前提知識や問題設定などについて書きます。
(※ この記事の執筆は aviatesk さんの許諾をいただいて行われています。ありがとうございます!)
束 (Lattice) の定義と具体例
少しだけ使う概念の準備を書いておきます。
束 (Lattice)
集合 \( L \) と \( L \) 上の二項関係 \( \leq \) が以下の条件を満たすとき、 \( (L, \leq) \) を束であるという。
とくに \( L \) が有限集合のとき、有限束という。
集合 \( L \) と \( L \) 上の二項関係 \( \leq \) が以下の条件を満たすとき、 \( (L, \leq) \) を束であるという。
- \( \leq \) が半順序である
- 各 \( x, y \in L \) について \( \{ x, y \} \) の上限と下限が常に存在する
とくに \( L \) が有限集合のとき、有限束という。
交わり(meet), 結び(join)
束 \( (L, \leq) \) について、
という。
束 \( (L, \leq) \) について、
- \( x, y \in L \) に対して \( \inf \{ x, y \} \) を \( x \) と \( y \) の交わり (meet)
- \( x, y \in L \) に対して \( \sup \{ x, y \} \) を \( x \) と \( y \) の結び (join)
という。
これだけだとパッとわかりにくいので、具体例を挙げてみます。
束の例1: 論理関数
束は割と色々なところに現れる構造です。
例えば、自分は論理回路理論の講義で束に出会いました。調べたらあまり例に上がっていなかったのと、この記事のメインと構造が同じことに気がついたのででここで書いてみます。
\( \mathbb{B} = \{ \text{0}, \text{1} \} \) として、 ( \( \text{0} \leq \text{1} \) です)
\( \mathbb{B}^n \to \mathbb{B} \) な関数全体の集合を \( \mathcal{F} \) とします。
\( f, g \in \mathcal{F} \) に対して次のように \( \mathcal{F} \) 上の二項関係 \( \leq \) を定義しましょう:
\[
f \leq g \Leftrightarrow \forall x \in \mathbb{B}^n, f(x) \leq g(x)
\]
このとき \( (\mathcal{F}, \leq) \) は束です。
確認してみます。
- \( \leq \) が半順序であること: これは一つずつ確認すると、それはそうです
- \( f, g \in \mathcal{F} \) に対して、 \( \{ f, g \} \) の上限と下限が存在すること: \( h(x) := \max \{ f(x), g(x) \} \) とすると、これは上限です。 \( h(x) := \min \{ f(x), g(x) \} \) とすると、これは下限です。
実際、例えば \( \mathbb{B} \to \mathbb{B} \) の関数全体の集合は
| \( x \) | \( f(x) \) | \( g(x) \) | \( h(x) \) | \( l(x) \) |
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 |
| 1 | 0 | 1 | 0 | 1 |
からなるわけですが、
以下のような図でその束の構造を表すことができます。
l
/\
/ \
/ \
/ \
h g
\ /
\ /
\ /
\/
f
つまり、ふんわり言うと束は上のような上下関係をいい感じの図にしたときに、どれをとっても下か上に辿れば交わるものと言えます。 (このような図を Hasse 図と言います。なお、全ての束が Hasse 図で表せるわけではないです (例えば \( \mathbb{R} \) と通常の大小関係))
なのでこういうグラフが得られているのであれば \( \inf \{a, b\} \) と \( \sup \{a, b\} \) を求めるのは LCA を求める問題に帰着します。
束の例2: Julia の型
Julia の型と、その親子関係による順序関係も束をなします。
\( L \) を Julia の型全体の集合とし、
\( L = \{ \text{Any}, \text{Number}, \text{Real}, \text{Int64} \cdots \} \)
二項関係 \( \leq \) を次のように定義します:
\( T \leq U \Leftrightarrow \) 型 \( T \) が型 \( U \) のサブタイプである
このとき \( (L, \leq) \) は束になります。
上に載せた図を作ることで直感的に確認しておきましょう、 「Julia Type Tree」 とかで検索するといい感じの図が出てきます。
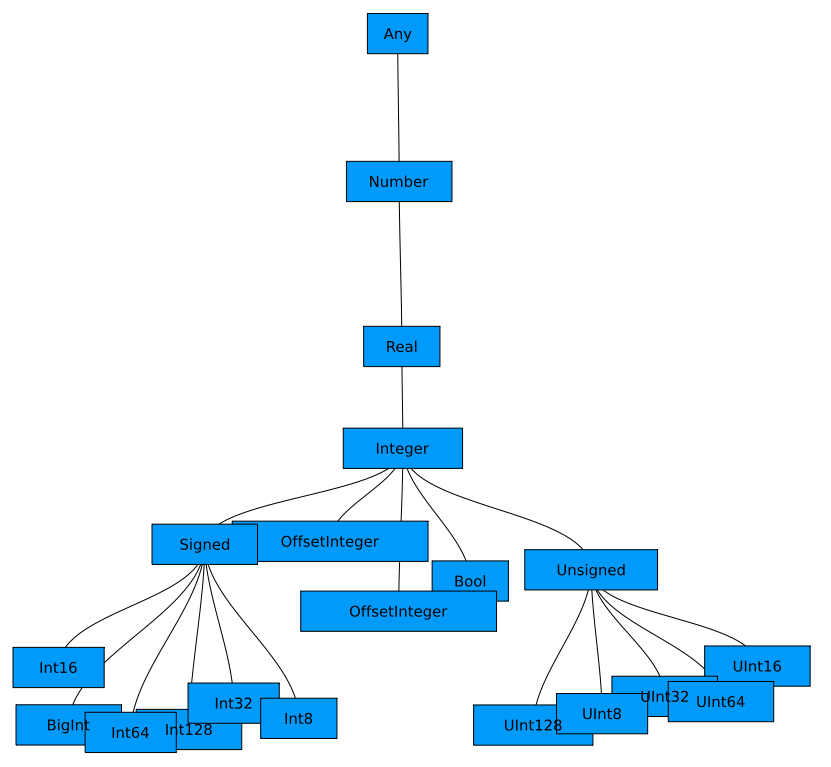
おかしいです! 束であるためには任意の 2つの元について下限が必要ですから、枝分かれのある木な訳がないです。
しかし Julia の Concrete Type は サブタイプを持たないはずです。どう言うことでしょうか?
──実は Julia の Concrete Type にサブタイプが存在しないと言うのが誤りで、
Union{} 型と言う型が存在してこれは任意の型のサブタイプになります。(
Union{} のオブジェクトは存在しません。型としてのみ存在します。)julia> Union{} <: Any
true
julia> Union{} <: Int64
true
したがって、任意の Concrete Type \( T, U \) に対して \( \inf \{ T, U \} = \text{Union\{\}} \) となります。
この型の存在によって Julia の型の階層関係は束をなします。
高さの有限性
さて、今後この束でプログラムのさまざまな抽象状態を表現するわけですが、その計算の複雑性を考える上で非常に重要な特徴があるのでここで導入します、
鎖 (Chain)
集合 \( L \) と \( L \) 上の二項関係 \( \leq \) を考える.
ここで、 \( P \subseteq L \) が任意の \( x, y \in P \) に対して \( x \leq y \) または \( y \leq x \) となるとき、 \( P \) を 鎖 といい、 \( |P| - 1 \) を鎖の 長さ という。
集合 \( L \) と \( L \) 上の二項関係 \( \leq \) を考える.
ここで、 \( P \subseteq L \) が任意の \( x, y \in P \) に対して \( x \leq y \) または \( y \leq x \) となるとき、 \( P \) を 鎖 といい、 \( |P| - 1 \) を鎖の 長さ という。
高さ
最小元 \( \bot \) が存在する半順序集合 \( (L, \leq) \) の元 \( x \) に対して、 \( [ \bot, x ] \subseteq L \) の鎖の長さの最大値を \( x \) の 高さ という。
さらに、 \( L \) の元の高さの最大値を Lの高さ という。
最小元 \( \bot \) が存在する半順序集合 \( (L, \leq) \) の元 \( x \) に対して、 \( [ \bot, x ] \subseteq L \) の鎖の長さの最大値を \( x \) の 高さ という。
さらに、 \( L \) の元の高さの最大値を Lの高さ という。
例えば
\[
\{ \text{Any}, \text{Number}, \text{Real}, \text{Int64} \}
\]
などは鎖で、長さは 3 です。
また、先ほど挙げた論理関数全体の集合がなす束の高さは 2 です。
では Julia の型 (に親子関係を入れたもの) は有限性条件を満たすでしょうか?
実は満たしません。無限上昇鎖を作ることができます。
これについては今後見ていきたいと思います。
さて、このように束は割といろんなところに現れる構造っぽいです。
そして、実はプログラムのさまざまな要素・状態を束で表現することでいろいろな性質の解析ができます。
ここからはそれを具体的に見ていきます。
抽象解釈
Julia の型推論アルゴリズムは抽象解釈と呼ばれる手法を使っています。
そこで、まずは 一旦 Julia の型推論のことは忘れて一般の抽象解釈についての話をしましょう。
まず前提として、プログラムの調べたい性質は大抵の場合 Undecidable で、静的解析をするには常に諦めもしくはある程度の抽象化が必要になります。
そこで、抽象解釈は読んで字の如し、プログラムをある程度抽象化して仮想的に実行することで、プログラムの性質を解析します。 つまり、抽象解釈という言葉は具体的なアルゴリズムというより、ある種のアプローチというかフレームワークというかを指す言葉です。
この抽象化の程度や方向性によって色々な解析をやっていくわけです。 例えば (役に立つのかはともかく、) 変数の偶奇だけに着目して「偶奇だけがわかるレベルで」プログラムを解釈して静的に偶奇の情報を得る、などができます。
元記事では定数畳み込みを抽象解釈を使って行っています。この記事でもまずはこの例を検討してみます。
抽象解釈による定数畳み込み: 問題設定
以下のような機能を持つ簡単な言語を考えます。
- 代入:
x := 1,r := y + z - goto:
goto line - 条件つき goto:
if x < 10 goto inst,if x ≤ z goto inst
簡単のために、代入の右辺は定数か変数またはそれらの二項演算のみで、値は全て整数とします。
例えば以下のような感じです。
0 ─ I₀ = x := 1
│ I₁ = y := 2
│ I₂ = z := 3
└── I₃ = goto I₈
1 ─ I₄ = r := y + z
└── I₅ = if x ≤ z goto I₇
2 ─ I₆ = r := z + y
3 ─ I₇ = x := x + 1
4 ─ I₈ = if x < 10 goto I₄
左についている枠について
命令列の左に枠がついていますが、これは基本ブロック (Basic Block) というものです。 基本ブロックは、文の列であって、分岐も合流もない、つまり一つの入り口と一つの出口を持つものをいいます。
これによってプログラム全体の流れを表したものを制御フローグラフ (Control Flow Graph) と言います。
プログラムが直列化されていれば goto, 条件付き goto によって分割することでこれが得られます。 (Julia では Lowering によってこれがされているんでした!このシリーズの過去記事を見てください。)
じっと見ると、以下のような処理をしていることがわかります。
x = 1
y = 2
z = 3
while x < 10
r = y + z
if !(x ≤ z)
r = z + y
end
x += 1
# @show x, y, z, r
end
手で実行してみると、こんな感じです.
| step | \( I \) | \( x \) | \( y \) | \( z \) | \( r \) | |
|---|---|---|---|---|---|---|
| 0 | \( I_0 \) | 1 | - | - | - | |
| 1 | \( I_1 \) | 1 | 2 | - | - | |
| 2 | \( I_2 \) | 1 | 2 | 3 | - | |
| 4 | \( I_8 \) | 1 | 2 | 3 | - | \( x < 10 \) なので \( I_4 \) にジャンプ |
| 5 | \( I_4 \) | 1 | 2 | 3 | 5 | |
| 6 | \( I_5 \) | 1 | 2 | 3 | 5 | \( x \leq z \) なので \( I_7 \) にジャンプ |
| 7 | \( I_7 \) | 2 | 2 | 3 | 5 | |
| 8 | \( I_8 \) | 2 | 2 | 3 | 5 | \( x < 10 \) なので \( I_4 \) にジャンプ |
| 9 | \( I_4 \) | 2 | 2 | 3 | 5 | |
| 10 | \( I_5 \) | 2 | 2 | 3 | 5 | \( x \leq z \) なので \( I_7 \) にジャンプ |
| 11 | \( I_7 \) | 3 | 2 | 3 | 5 | |
| 12 | \( I_8 \) | 3 | 2 | 3 | 5 | \( x < 10 \) なので \( I_4 \) にジャンプ |
| 13 | \( I_4 \) | 3 | 2 | 3 | 5 | |
| 14 | \( I_5 \) | 3 | 2 | 3 | 5 | \( x \leq z \) なので \( I_7 \) にジャンプ |
| 15 | \( I_7 \) | 4 | 2 | 3 | 5 | |
| 16 | \( I_8 \) | 4 | 2 | 3 | 5 | \( x < 10 \) なので \( I_4 \) にジャンプ |
| 17 | \( I_4 \) | 4 | 2 | 3 | 5 | |
| 18 | \( I_5 \) | 4 | 2 | 3 | 5 | \( x \leq z \) ではないのでジャンプはしない |
| 19 | \( I_6 \) | 4 | 2 | 3 | 5 | |
| 20 | \( I_7 \) | 5 | 2 | 3 | 5 | |
| 21 | \( I_8 \) | 5 | 2 | 3 | 5 | \( x < 10 \) なので \( I_4 \) にジャンプ |
| 22 | \( I_4 \) | 5 | 2 | 3 | 5 | |
| 23 | \( I_5 \) | 5 | 2 | 3 | 5 | \( x \leq z \) ではないのでジャンプはしない |
| 24 | \( I_6 \) | 5 | 2 | 3 | 5 | |
| 25 | \( I_7 \) | 6 | 2 | 3 | 5 | |
| 26 | \( I_8 \) | 6 | 2 | 3 | 5 | \( x < 10 \) なので \( I_4 \) にジャンプ |
| ... | ... | ... | ... | ... | ... | ... |
| 45 | \( I_5 \) | 10 | 2 | 3 | 5 | \( x < 10 \) でないのでジャンプはしない. 終了 |
x をループカウンタとして使いつつ、最後の 10 - z 回は r = z + y もする、みたいなコードです (これは何?)さて、ここから以下の事実を静的解析によって見つけることが目標です:
y , z , r は定数である データフロー解析の形式的定義
このあと具体的なアルゴリズムに入る前に、もう少し解こうとしている問題をもう少し一般化して定式化してみます。
今回解きたい問題は、以下のように定義される 「データフロー解析」 と呼ばれる抽象解釈によって解ける問題の一つとして捉えることができます。
データフロー解析は、簡単に言えば次のような問題を解くことです。
- 命令 \( i \) の直前/直後の抽象状態として、最も具体的なものを求めよ。
実際に計算機上で解くために、形式的に定義してみましょう。
データフロー解析 (Data Flow Analysis)
命令全体の集合を \( \text{Instr} \) 、プログラムの状態全体の集合を \( A \) とする。
\( \text{Instr} \) は
のいずれかに属する命令の集合。
ここで、以下のような四つ組 \( (P, L, ![.!], a_0) \) を考える:
このとき、データフロー解析は以下のような問題を解くことである:
\( \text{Pred}_P: \{1, 2, \cdots, n\} \to 2^{\{1, 2, \cdots, n\}} \) を
と定めたとき、連立方程式
を満たす最大の解 \( s_1, s_2, \cdots, s_n \) を求めよ
命令全体の集合を \( \text{Instr} \) 、プログラムの状態全体の集合を \( A \) とする。
\( \text{Instr} \) は
- 代入
- goto
- 条件つき goto
のいずれかに属する命令の集合。
ここで、以下のような四つ組 \( (P, L, ![.!], a_0) \) を考える:
- \( P = I_1, I_2, \cdots, I_n \in \text{Instr} \) : プログラム (命令の有限列)
- \( L = (A, \leq) \) : 高さが有限の束
- \( ![.!] \in \text{Instr} \to (A \to A) \) : 各命令の作用を表す単調関数を返す関数
- \( a_0 \in A \) : 初期状態
このとき、データフロー解析は以下のような問題を解くことである:
\( \text{Pred}_P: \{1, 2, \cdots, n\} \to 2^{\{1, 2, \cdots, n\}} \) を
\[
j \in \text{Pred}_P(i) \Leftrightarrow
I_j \in \{ \text{goto i}, \text{条件つき goto i} \} \text{ または } j = i - 1 \ かつ\ I_i \neq \text{goto}
\]
と定めたとき、連立方程式
\[
s_i = \prod_{j \in \text{Pred}_P(i)}  \quad (i = 1, 2, \cdots, n)
\]
を満たす最大の解 \( s_1, s_2, \cdots, s_n \) を求めよ
少し補足をします。
- 状態 \( s \in A \) のときに 命令 \( I \) を実行したときの状態は \(  \) です (記法の確認です)
-
\bigsqcapが MathJax で使えなかったので \( \prod \) で代用しています。交わりの意味です。 - つまり、 連立方程式の各方程式はつまるところ「ありうる直前命令からの実行結果の全ての交わり」と言うことになります。
- \( \text{Pred}_P(i) \) はややこしくなっていますが、要は命令 \( I_i \) の直前になりうる命令のインデックスの集合になります。
- 果たしてこれは最初に書いた「命令 \( i \) の直前/直後の抽象状態として、最も具体的なものを求めよ」に対応する妥当な定義でしょうか?実はとても議論の余地、というか抜けがあります。次回の記事で議論するので、一旦ここは置いておいてください。
- 元記事や
元論文 では \( L \) を その交わりと結びで定義していますが、ここでは準備に合わせて \( (A, \leq) \) としています。 - 順序関係が \( A \) 上で定まっていることに注意しましょう。 (後述します)
定数畳み込みの形式的定義
実際に今回の問題をこの定義に落とし込みます。
上から行きましょう。
1. \( \text{Instr} \)
ちゃんと定義したければ BNF とかを書けばいいと思いますがいったんふわっと書くと
\[
\begin{align*}
\text{Instr} =\ &\{ \\
&x := 1, \\
&x := 1 + y, \\
&\text{goto 1}, \\
&\text{if } x < 10 \text{ goto 2}, \\
&\vdots \\
\}
\end{align*}
\]
みたいな集合です。全ての要素はそれぞれ 代入, goto, 条件つき goto のどれかただ一つに属することに注意してください。
代入文の右辺には定数、変数またはそれらの二項演算がきます。( \( n \) 項演算に拡張するのは容易ですが説明のために簡単にしています)
2. \( A, \leq \)
次はプログラムの状態 \( A \) とその順序関係 \( \leq \) です。
今回の設定では変数の状態以外に特に状態はありませんから、
\( X \) を変数の集合、 \( C \) を変数の状態の集合として
\( A = X \to C \) とすればいいでしょう。
今さらっと \( C \) を導入しましたが、ここが (多分自分が思うに) キモです。 これの中身をどうするかが抽象解釈の設計の本質パート (ではないかとと素人ながら) 思います.
というのもこの部分こそが調べたい性質のためにプログラムを抽象化するパートだからです。
例えば今回の場合、次のような集合と順序関係を考えることによって抽象化します。
\( L = \{ \bot, 1, 2, 3, \cdots, \top \} \) として、 \( L \) 上の順序関係 \( \leq \) を次のように定義します:
\[
l_i \leq l_j \Leftrightarrow l_i = l_j \text{ または } l_i = \bot \text{ または } l_j = \top
\]
このとき \( (L, \leq) \) は束です。
図にすると
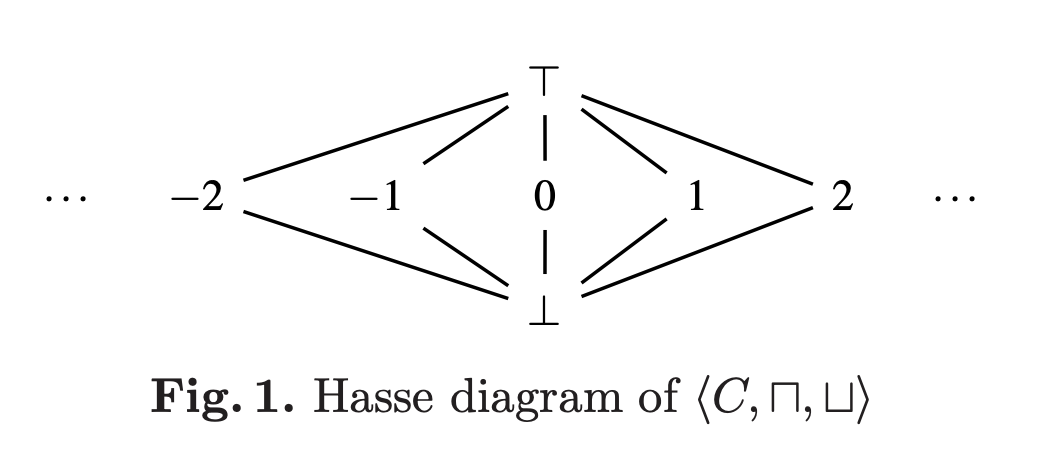
みたいな感じです。
\( \bot, \top \) はそれぞれ次のような意味です。 [1]
- \( \bot \) : 定数でない
- \( \top \) : 未定義
このような状態 \( C \) を設定することで、実際の実行から、「定数かどうか && 定数ならその値」を考える抽象的な解釈に落とし込まれるわけです! (たぶん)
例えば (そんなもんが役に立つのかはさておき) 単に「定数かどうか」だけ調べるのであれば \( C = \{ \bot, c, \top \} \) みたいな感じでいいのだと思います。
なお、注意する点として、 データフロー解析の問題設定においてはあくまでも束をなのは 各変数でなく状態 \( A \) と \( A \) 上の順序です。
したがって \( A \) 上の順序関係を考える必要があります。
が、そこまで大変でなく単に次のようにすればいいです。
\[
a_i \leq a_j \Leftrightarrow \forall x \in X, a_i(x) \leq a_j(x)
\]
これが束をなすのは論理関数のときと同じような感じでわかります! (一般に、束の直積は上のように順序関係を定義することで束になります)
なお、次の記事で使うのでここでいくつかメモ書きをしておきます。 (また、これ以降では記法の煩雑さ回避のために全ての変数が共通の状態 \( l \) である抽象状態 \( C: X \mapsto l \) を単に \( l \) と書きます.)
- meet の単位元は \( \bot \) です
- join の単位元は \( \top \) です
- \( C \) は有限性条件を満たします. (長さが最大の鎖は \( \bot \leq c \leq \top \) です)
3. \( ![.!] \)
構文は 3種類に分かれているわけですが、それぞれについて考えればいいです。
[代入]
x := expr としたとき、 \( x \) 以外の変数の状態は変わりません。右辺に現れるのが全て定数( \( \neq \bot \) ) であれば
x も定数になりますから、 \( s' =  \) は次のようになります。 \[
a =
\begin{cases}
\text{expr} & \text{右辺がすべて定数} \\
\bot & \text{otherwise}
\end{cases}
\]
として、
\[
s'(x) = \begin{cases}
\text{a} & x = \text{\text{var}} \\
s(x) & \text{otherwise}
\end{cases}
\]
[goto]
何も変わらないです。
[条件つき goto]
何も変わらないです。
4. \( a_0 \)
初期状態は全ての変数が \( \top \) です。 元記事によれば元論文が間違っているとのことです。自分が一から読んでいたら気がつけないだろうことなので、ありがたいです。。。
まとめ !?
こうして今回の問題設定をデータフロー解析の形式的定義に落とし込むことができました。
次回は実際にこれを解くアルゴリズムを紹介します。